AI SEO: Hur du rankar i AI Overviews och AI-sökresultat

SEO har alltid handlat om att ligga steget före Googles algoritmer, förstå vad människor söker efter och skapa innehåll som matchar deras behov. Målet har varit att synas högt i sökresultaten och driva trafik genom traditionella blå länkar.
Men sökbeteendet håller på att förändras. I dag får allt fler människor svar på sina frågor direkt via ChatGPT, Gemini, Copilot, Grok och andra AI-verktyg.
AI-sökmotorer fungerar inte som traditionell Google-sökning. De visar inte bara en lista med länkar, utan läser, väger samman och sammanfattar information från många olika källor för att ge användaren ett direkt svar. I vissa fall hänvisar de till sina källor, i andra fall gör de det inte.
Om ditt innehåll inte syns i AI-genererade svar riskerar du att bli osynlig för en snabbt växande publik. I den här guiden går vi igenom vad AI SEO är, hur AI-sök faktiskt fungerar och vad du kan göra för att öka chansen att ditt innehåll blir synligt.
TL:DR:
”AI SEO handlar om att optimera innehåll så att det inte bara syns i traditionella sökresultat, utan också kan upptäckas, förstås och användas i AI-genererade svar. Grunden är fortfarande klassisk SEO, men i AI-sök blir tydlig struktur, teknisk tillgänglighet, auktoritet och innehåll som är lätt att extrahera ännu viktigare. Den här artikeln går igenom hur AI-sök fungerar, hur det skiljer sig från traditionell sök och vad du konkret behöver göra för att öka din synlighet i AI-drivna sökmiljöer.”
Vad är AI SEO?
AI SEO är processen att optimera din webbplats och ditt innehåll så att det blir lättare att upptäcka, förstå, citera och rekommendera i AI-drivna sökmiljöer. Det gäller exempelvis ChatGPT, Google AI Overviews, Gemini och andra AI-verktyg som genererar svar utifrån innehåll på webben.
I grunden bygger AI SEO fortfarande på samma principer som traditionell SEO: användbart innehåll, teknisk kvalitet, tydlig struktur och stark auktoritet. Skillnaden är att innehållet också behöver fungera väl i miljöer där AI-system tolkar, sammanfattar och lyfter fram information direkt i sina svar.
Många tror att AI SEO ersätter traditionell SEO, men så är det inte. Snarare är det en vidareutveckling av samma grundarbete. AI SEO bygger ovanpå klassisk SEO och hjälper företag att arbeta med en mer samlad strategi för både traditionell söksynlighet och synlighet i AI-drivna upplevelser.
Ny terminologi inom SEO
När söklandskapet förändras kommer också nya begrepp. I takt med att AI-sök växer fram har branschen börjat använda flera olika termer för att beskriva liknande arbetssätt. Det finns ännu inte ett enda etablerat namn, vilket gör att samma typ av optimering kan beskrivas på olika sätt beroende på vem du läser.
Termerna har något olika fokus, men de kretsar i grunden kring samma fråga: hur optimerar man innehåll för att bli synlig i AI-driven sökning?
- AI SEO är det bredaste paraplybegreppet. Det omfattar alla strategier som syftar till att göra innehåll upptäckbart, begripligt och citeringsbart i AI-drivna sökplattformar.
- GEO (Generative Engine Optimization) fokuserar främst på att göra innehållet synligt i AI-genererade svar och sammanfattningar. Om ett AI-system sammanställer ett svar från flera olika källor handlar GEO om att öka chansen att ditt innehåll blir en av dem.
- AEO (Answer Engine Optimization) handlar om att optimera innehåll för direkta svar. Det kan till exempel gälla utvalda utdrag, röstassistenter eller AI-verktyg som hämtar tydliga och konkreta svar från en sida.
- LLMO (Large Language Model Optimization) fokuserar på hur stora språkmodeller tolkar, förstår och refererar till ditt innehåll eller ditt varumärke.
- NLP (Natural Language Processing) är egentligen inte en optimeringsmetod, utan tekniken bakom hur AI-system förstår språk. Begreppet används ändå ofta i sammanhang där man diskuterar hur AI analyserar frågor och matchar dem med relevant innehåll.
Det finns fler begrepp än dessa, och gränserna mellan dem är ofta otydliga. I praktiken används många av termerna nästan som synonymer, eftersom branschen ännu inte helt har enats om ett gemensamt språk. Just nu är AI SEO det tydligaste paraplybegreppet för området som helhet.
Varför AI SEO är viktigt
Människor söker annorlunda nu
Sök har förändrats. AI-sök är inte längre en avlägsen framtid som vi väntar på, utan något som redan är här. Moderna sökalgoritmer blir allt mer komplexa, och Google använder i dag över 200 rankingfaktorer samt gör tusentals algoritmjusteringar varje år. Samtidigt möter användare i allt högre grad AI-sammanfattningar och multimodala resultatblock innan de når de traditionella organiska träffarna i SERP:en.
De här upplevelserna har redan förändrat hur människor upptäcker varumärken, produkter och fattar beslut.
- ChatGPT hanterar över 2,5 miljarder användarinstruktioner varje dag.
- Google visar AI-översikter på ungefär 60% av alla sökningar.
- 44% använder AI i stället för traditionell sök.
- AI drev en trafikökning på 4 700 procent till retail-sajter under sommarsäsongen 2025.
Det här är inte längre en nischpublik. Det handlar om vanliga användare, potentiella kunder och beslutsfattare som redan har börjat ändra sitt sökbeteende. Om ditt innehåll inte syns i AI-genererade svar riskerar du att missa en växande kanal för upptäckt, påverkan och trafik. McKinsey varnar också för att oförberedda varumärken kan ha 20–50 procent av sin traditionella söktrafik i riskzonen
De flesta sökningar får redan noll klick
Nollklickssökningar har blivit en central del av dagens sökbeteende. Under 2024 slutade 58,5 procent av Google-sökningarna utan klick. När en AI-sammanfattning visades klickade användare dessutom på ett traditionellt sökresultat i bara 8 procent av besöken, jämfört med 15 procent när ingen AI-sammanfattning visades.
Det här förändrar hur SEO-framgång behöver mätas:
- Organisk trafik kan minska även när synligheten ökar.
- Närvaro i AI-svar blir en viktig signal, inte bara ranking och klick.
- Innehållets kvalitet, tydlighet och auktoritet avgör om din information lyfts fram.
- Informationssökningar högre upp i tratten påverkas mest, medan mer transaktionsnära sökningar ofta är stabilare. McKinsey skriver att mer än 70 procent av AI-sökanvändarna ställer frågor i toppen av tratten.
AI SEO handlar därför inte längre bara om att få fler klick. Det handlar om att vara synlig där användaren faktiskt får sitt svar och börjar fatta sitt beslut. Därför måste synlighet i både klassiska sökresultat och AI-genererade svar ses som en del av samma arbete.
Hur AI-sök fungerar?
AI-sök fungerar vanligtvis i flera steg. Först tolkar systemet användarens fråga och kan skriva om eller förbättra den. Därefter hämtar det relevanta dokument eller textpassager ur en större mängd information. Sedan rangordnas resultaten så att de mest relevanta kommer högst upp. I vissa fall används de hämtade källorna också för att generera ett färdigt svar och för att visa vilka källor svaret bygger på (37).
Informationsåtervinning (IR) kan ske i många olika former, till exempel genom textfrågor, frågesuggestioner, röst eller bilder (36). Om en fråga är oklar kan systemet använda användarens historik, geografiska plats, förändringar i information över tid och andra typer av kontext för att presentera mer relevanta resultat (36).
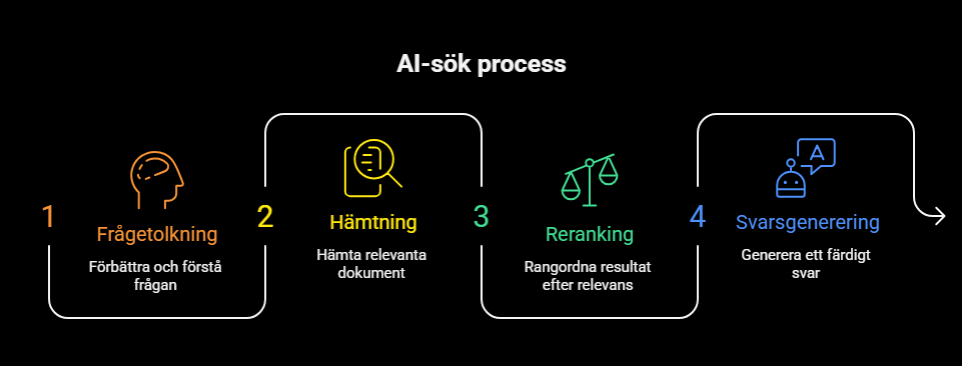
En vanlig arkitektur i moderna AI-söksystem består alltså av flera steg: frågetolkning och frågeförbättring → hämtning→ reranking → svarsgenerering → källhänvisning och utvärdering (37).
Frågetolkning och frågeförbättring
Det första steget är inte alltid att söka direkt. I många fall är användarens fråga för kort, tvetydig eller dåligt anpassad för sökning. Därför kan moderna AI-söksystem först skriva om frågan, expandera den med fler relevanta termer eller dela upp den i flera delproblem innan hämtningen sker.
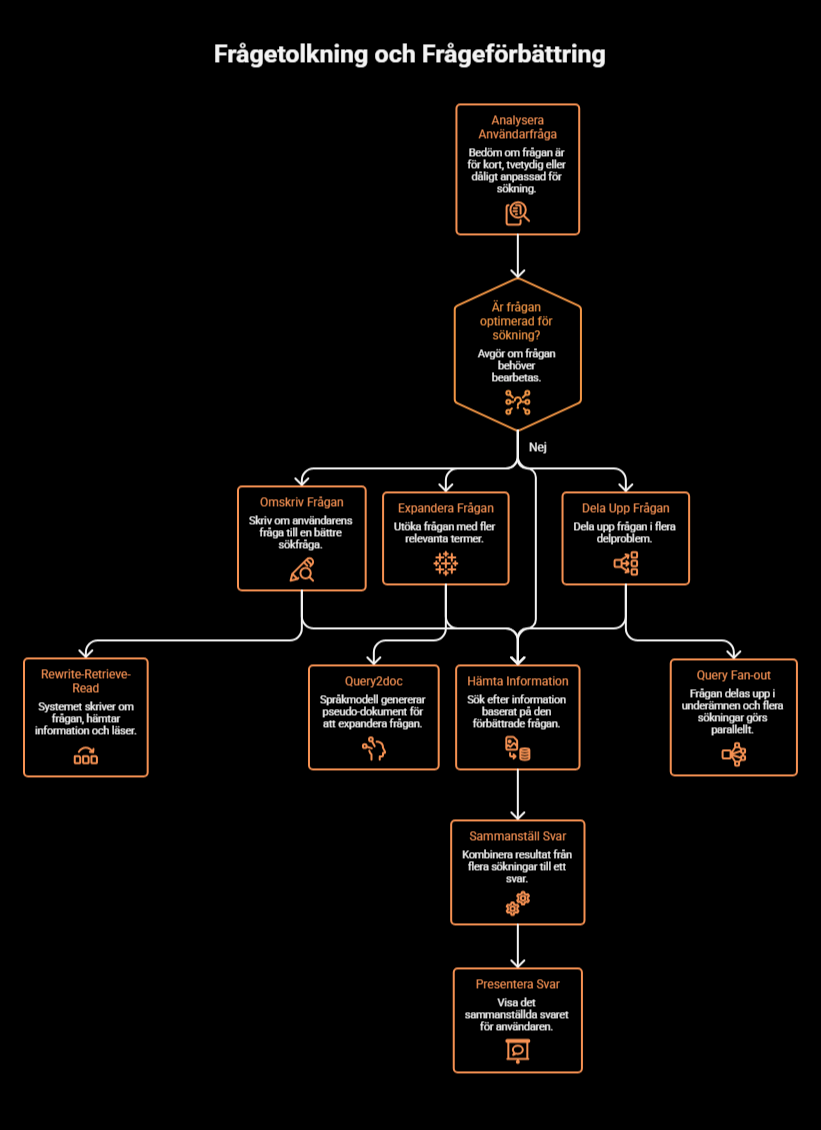
Ett exempel är Rewrite-Retrieve-Read, där systemet först skriver om användarens fråga till en bättre sökfråga innan information hämtas (21). Ett annat exempel är Query2doc, där en språkmodell genererar pseudo-dokument som används för att expandera frågan och göra den mer informativ för retrievern (35). I praktiken används också liknande tekniker i kommersiella system. Google beskriver till exempel att AI Mode använder query fan-out, där frågan delas upp i underämnen och flera sökningar görs parallellt innan resultaten sätts samman till ett svar.
Det här steget är viktigt eftersom systemet då inte bara söker efter exakt det användaren skrev, utan försöker översätta frågan till en form som är bättre anpassad till själva sökningen.
Hämtning: hur systemet hämtar relevanta källor
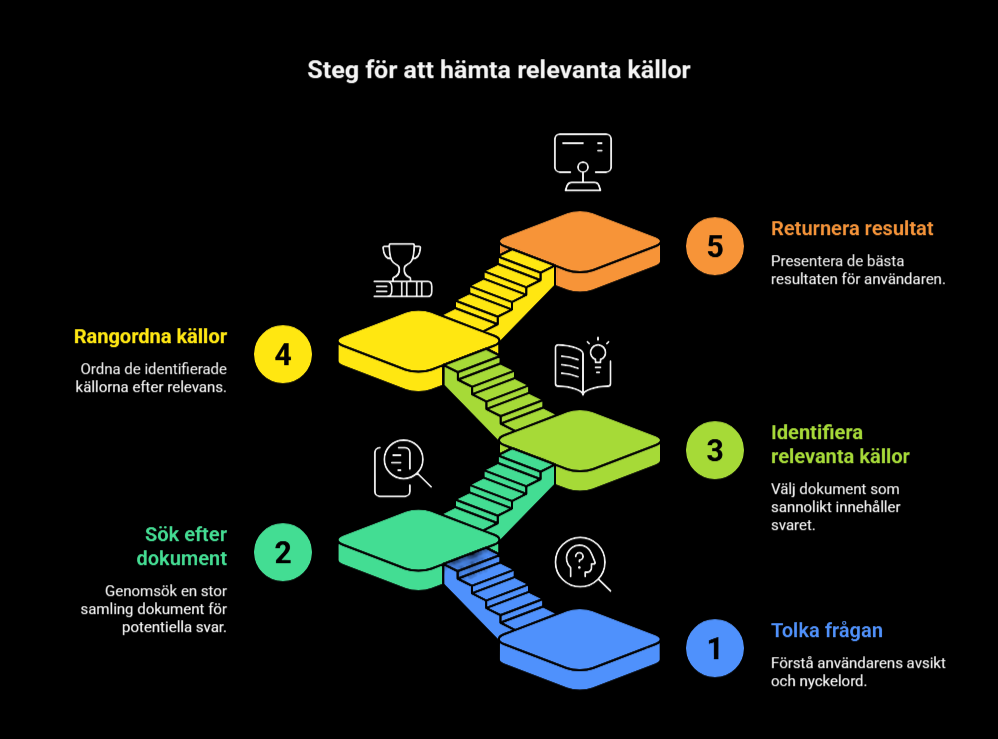
När frågan väl har tolkats försöker systemet hitta dokument eller textpassager som kan innehålla svaret. Detta steg kallas retrieval. Här är målet att snabbt hämta fram ett antal relevanta kandidater ur en mycket stor samling dokument.
Frågebesvarande system kan fungera på olika sätt: de kan välja rätt svar från flera alternativ, avgöra om något är sant eller falskt (29), hitta det textavsnitt som bäst besvarar frågan (28), eller samla information från en eller flera källor och därefter formulera ett eget svar (25).
När en användare skriver en sökfråga söker IR-systemet därför igenom många möjliga dokument eller textavsnitt, identifierar de som kan besvara frågan (34), även när de inte använder exakt samma ord (20), rangordnar dem efter relevans (20) och returnerar de bästa resultaten.
Dense Passage Retrieval (DPR)
DPR gör om både frågor och textpassager till täta vektorer i ett gemensamt rum. På så sätt kan systemet hämta relevanta passager utifrån betydelse, inte bara utifrån exakta ordmatchningar (15).
SPLADE
SPLADE är en modell som lär sig vilka ord i ordförrådet som är viktigast för att representera en fråga eller ett dokument. Den behåller därmed fördelen med termbaserad sökning och exakta ordmatchningar, men använder samtidigt en språkmodell för att förbättra relevansen (7).
ColBERT
ColBERT ligger mellan enklare dense retrieval och mer avancerad sen interaktion mellan fråga och dokument. Modellen representerar frågan och dokumentet var för sig, men jämför dem sedan mer detaljerat i ett senare steg. Det gör det möjligt att kombinera hög träffsäkerhet med bättre effektivitet (16).
Reranking: hur resultaten omordnas efter relevans
När retrieval-steget har hämtat fram ett antal möjliga kandidater kan ett nytt steg ta vid: reranking. Här går systemet igenom de redan hämtade dokumenten eller passagerna och försöker avgöra vilka som faktiskt är mest relevanta.
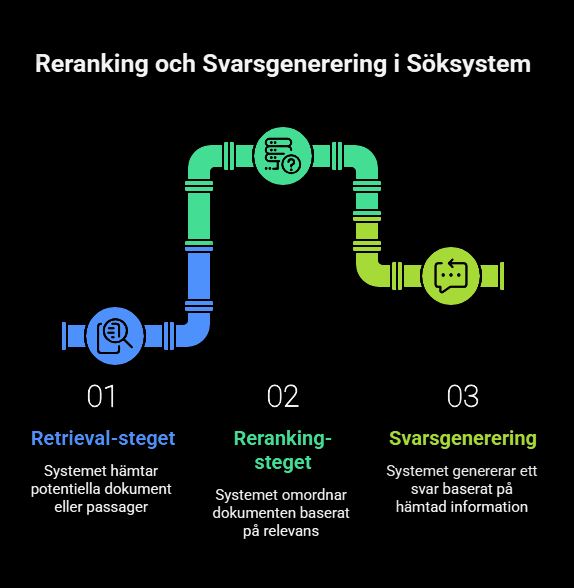
BERT passage re-ranking är ett tydligt exempel på detta. Där hämtar ett traditionellt söksystem först många möjliga dokument eller passager. Därefter läser en språkmodell frågan tillsammans med varje passage och rangordnar dem på nytt efter hur relevanta de verkar vara (26). BERT används alltså inte främst för att söka i hela samlingen från början, utan för att förbättra ordningen på resultat som redan har hämtats.
Svarsgenerering med Retrieval-Augmented Generation (RAG)
I vissa system räcker det inte att bara visa dokument eller passager. Systemet förväntas också formulera ett färdigt svar. Då används ofta de hämtade källorna som underlag för generering.
Ett konkret exempel är Retrieval-Augmented Generation (RAG), där systemet först hämtar relevant information från en extern kunskapskälla och sedan använder den informationen för att generera ett svar (18). På så sätt kombineras språkmodellens interna kunskap med extern, upphämtad kunskap. Detta kan ge mer faktabaserade och mer uppdaterbara svar än om modellen enbart skulle förlita sig på sitt interna minne.
Ett fel i retrieval-steget eller ett svagt utnyttjande av den hämtade kontexten kan därför leda till ett övertygande men otillräckligt underbyggt svar (9;5). RAG-system behöver därför inte bara stark retrieval, utan också god förmåga att använda den hämtade kontexten på ett troget sätt.
Varför AI-sök skiljer sig från traditionell sökning
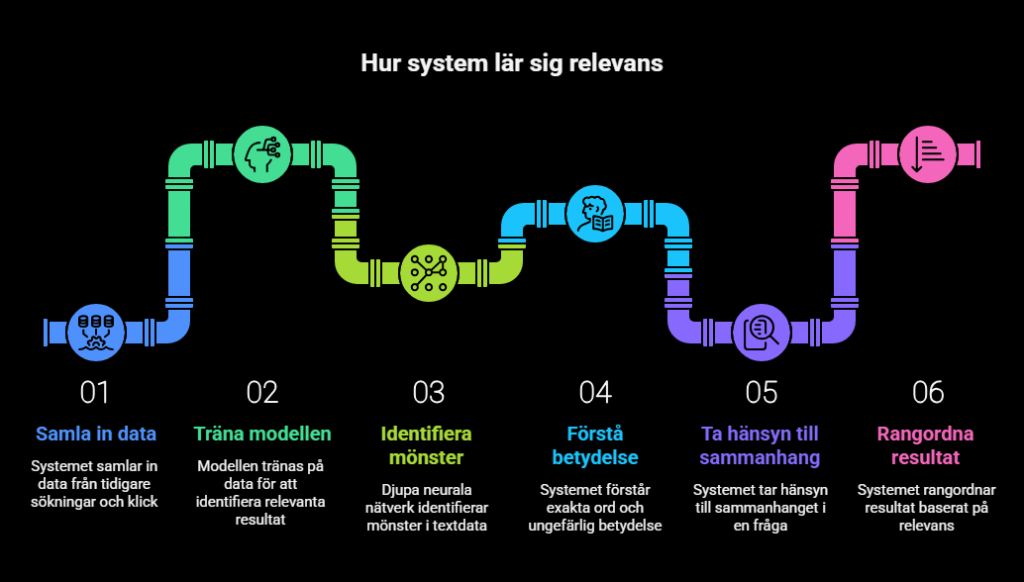
Till skillnad från traditionell sökning, som ofta bygger på exakta ordmatchningar (30), försöker AI-sök förstå vad användaren menar. Systemet lär sig detta genom att upptäcka mönster i stora mängder text: ord som ofta används i liknande sammanhang får liknande betydelse (13), och ord som ofta förekommer tillsammans kopplas till samma ämne (17). Därför kan AI-sök hitta relevanta svar även när dokumentet inte innehåller exakt samma ord som i sökfrågan (19).
Sättet AI får fram relevanta resultat bygger alltså på att systemet lär sig vilka ord och uttryck som ofta hör ihop. På så sätt kan det förstå att olika ord ibland kan handla om samma sak, även om de inte är identiska. Det gör att söksystemet inte bara letar efter exakta ord, utan också efter innehåll som liknar frågans betydelse eller ämne (13;14).
Hur systemen lär sig vad som är relevant
För att avgöra vilka resultat som ska visas högst upp tränas systemen på många exempel. De kan till exempel lära sig från tidigare sökningar, klick eller andra signaler som visar vilka resultat som har varit mest hjälpsamma för användare (14). Med hjälp av dessa exempel lär sig modellen steg för steg att ge högre poäng till dokument som verkar mer relevanta och lägre poäng till dokument som verkar mindre relevanta (20).
Djupa neurala nätverk används för att hitta sådana mönster i stora mängder text (31). Enkelt förklarat gör de om ord och dokument till siffror, bearbetar dem i flera steg och lär sig sedan vilka kombinationer som ofta leder till bra sökresultat (31). På så sätt kan systemet både förstå exakta ord, tolka ungefärlig betydelse och ta hänsyn till sammanhanget i en fråga (24).
Källhänvisning och utvärdering i AI-sök
För att förstå om ett AI-söksystem faktiskt fungerar bra räcker det inte att titta på en enskild modell. Systemet måste också utvärderas som helhet. Här används både klassiska IR-mått och särskilda benchmarkar.
BEIR är viktigt därför att det visar hur olika retrievalmetoder fungerar över många olika dataset och domäner. Resultaten visar att BM25 förblir en stark och robust baseline, medan mer avancerade metoder som re-ranking och late interaction ofta ger bättre resultat i många settingar, men till högre beräkningskostnad (33).
För system som inte bara hämtar dokument utan också genererar svar med källor behövs dessutom andra typer av utvärdering. ALCE har utvecklats för att mäta långtextsvar med citat längs dimensionerna flyt, korrekthet och citeringskvalitet, medan RAGAS är ett ramverk för referensfri utvärdering av RAG-pipelines och försöker bedöma både retrieval-kvalitet, hur väl modellen använder kontexten och kvaliteten på det genererade svaret 8;5).
Det här är viktigt eftersom ett svar kan låta övertygande men ändå vila på svaga, ofullständiga eller felaktiga källor.
AI SEO vs traditional SEO
AI sökmotoroptimering och den tranditionella sökmotoroptimering i grunden fungerar på samma sätt. Båda belönar högkvalitativ innehåll, starkt innehåll och bra tekniska grunder. Men de mäter framgång på olika sätt och kräver olika sätt att tänka kring synlighet.
Det som förblir detsamma:
- Kvalitativt innehåll vinner fortfarande. Tunt, ytligt eller svagt innehåll presterar dåligt i båda miljöerna. AI-system föredrar att citera källor som är genuint hjälpsamma, välformulerade och tillräckligt djupgående
- Sökintentionen är fortfarande central. Innehåll som tydligt svarar på användarens fråga, behov eller problem fungerar bättre både i traditionell sök och i AI-drivna svar.
- Auktoritet och förtroende spelar fortfarande stor roll. Bakåtlänkar, varumärkesomnämnanden och signaler kopplade till E-E-A-T stärker både din synlighet i traditionella sökmotorer och sannolikheten att bli refererad av AI-system.
- Teknisk hälsa är fortfarande grunden. Snabba laddningstider, mobilanpassning, korrekt rendering och god crawlbarhet är grundkrav för att lyckas i både sök och AI-drivna miljöer.
- Ämnesdjup och topical authority spelar fortsatt stor roll. Webbplatser som täcker ett område brett och konsekvent uppfattas fortfarande som mer relevanta och trovärdiga.
- Intern länkning och tydlig webbplatsstruktur är fortsatt viktigt. Ämneskluster, logisk struktur och stark intern länkning hjälper både sökmotorer och AI-system att förstå bredden och djupet i din expertis.
Vad förändras med AI sökning?
- Rankingar blir citeringar. I traditionell SEO mäts synlighet ofta i var du rankar i sökresultatet. I AI-sök handlar synlighet i stället om ditt innehåll blir citerat, refererat eller används som källa i AI-genererade svar.
- Svaren blir viktigare än länkarna. I traditionell sök konkurrerar sidor om att få klick från en lista med länkar. I AI-sök konkurrerar innehåll i högre grad om att bli en del av själva svaret.
- Nyckelord blir koncept. Traditionell SEO har länge kretsat kring specifika sökord och sökfraser. AI-system försöker i högre grad förstå betydelsen bakom frågan, sammanhanget och användarens intention, inte bara exakta ordmatchningar.
- Klick blir omnämnden. I traditionell sökning leder synlighet ofta till klick vidare till din webbplats. I AI-sök sker mycket av synligheten utan klick. Ditt varumärke kan nämnas, citeras eller påverka svaret utan att användaren någonsin besöker din sajt.
- En sökfråga blir en konversation. I Google skriver användaren oftast en fråga och får en lista med länkar. I AI-sök bryts frågan ofta ner i flera delfrågor, som vägs samman till ett mer komplett svar. Det gör sökbeteendet mer dynamiskt och mer likt en dialog än en traditionell sökning.
- Stabila positioner blir återkommande närvaro. Googles rankingar är ofta relativt stabila och möjliga att följa över tid. AI-svar varierar mer beroende på hur frågan formuleras, vilket sammanhang som ges och vilka källor modellen väljer att använda. Därför blir det viktigare att mäta hur ofta du dyker upp än vilken exakt position du har.
- Flera källor vägs ihop i samma svar. I stället för att användaren själv jämför flera olika sidor gör AI-systemet en första sammanvägning åt användaren. Det betyder att du inte bara konkurrerar om uppmärksamhet, utan också om att få bidra till helhetsbilden.
Du behöver inte välja
Med framväxten av nya termer och olika sätt att optimera för AI är det lätt att bli förvirrad. Det kan kännas som att man måste välja mellan att optimera sitt innehåll för traditionell Google-SEO eller för AI-sökmotoroptimering. Men det stämmer inte. Du behöver inte välja. Den bästa strategin är istället att kombinera båda.
Kenichi Suzuki postade på sin linkedin ‘’För att få ditt innehåll att synas i AI-översikten, använd helt enkelt vanliga SEO-metoder. Du behöver inte GEO, LLMO eller något annat.’’
Enligt Google krävs inga särskilda AI-optimeringar för att synas i AI Overviews eller AI Mode. Vanliga SEO-grunder gäller fortfarande.
AI SEO är inte en ersättning för traditionell SEO, utan ett nytt lager ovanpå den. Grunden är densamma, men strategin behöver breddas.
Hur man optimerar för AI-sökning
Se till att AI-botar kan läsa ditt innehåll
Det viktigaste steget, både för AI-sök och för sökning generellt, är att dina sidor faktiskt går att crawla och läsas. Om botarna inte kommer åt innehållet spelar inget annat någon roll. Google lyfter själva fram detta som en grundförutsättning för synlighet i AI Overviews och AI Mode.
Många webbplatser blockerar AI-botar utan att vara medvetna om det. Gå därför igenom din robots.txt och säkerställ att du inte av misstag stoppar relevanta crawlers. Om du använder Cloudflare bör du kontrollera inställningarna extra noggrant, eftersom nya domäner numera får ett uttryckligt val om AI-crawlers ska tillåtas eller nekas.
Även om din robots.txt är rätt inställd kan AI-botar fortfarande blockeras av servern, ditt CDN eller olika säkerhetsinställningar. Därför räcker det inte att bara kontrollera robots.txt, du behöver också se över brandväggar, bot-skydd och andra tekniska spärrar som kan stoppa crawlers.
Se till att det viktigaste innehållet finns tillgängligt direkt i HTML. Om innehållet göms bakom JavaScript ökar risken att botar inte läser det korrekt.
Kontrollera att du inte blockerar innehållet med andra signaler. Även om sidan går att crawla kan synligheten fortfarande begränsas av till exempel noindex, nosnippet, inloggningsväggar, 403-svar, CAPTCHA eller andra tekniska spärrar. Därför räcker det inte att sidan är åtkomlig, du måste också säkerställa att innehållet faktiskt får visas och användas i sökresultat och AI-svar.
Implementera llms.text på sidan
När du har säkerställt att AI-botar kan besöka, och läsa din webbplats är nästa steg att göra innehållet ännu lättare att förstå. Här kan en llms.txt-fil fungera som ett komplement. Tanken med llms.txt är att ge språkmodeller en tydlig översikt över webbplatsens viktigaste innehåll, sidor och resurser i ett enkelt format. Specifikationen beskriver det som en föreslagen standard för att hjälpa LLM:er att använda en webbplats vid inferens.
Så bör du arbeta med llms.txt:
- Skapa en tydlig översikt över webbplatsen. Använd llms.txt för att sammanfatta vad webbplatsen handlar om, vilka huvudområden den täcker och vilka sidor som är viktigast. Målet är att göra det lättare för AI-system att snabbt förstå strukturen och innehållet.
- Lyft fram de viktigaste resurserna. Länka till centrala sidor, guider, dokumentation, kategorier eller andra resurser som du vill att modeller lättare ska hitta. Filen ska fungera som en karta till det mest värdefulla innehållet på sajten.
- Håll innehållet kort, tydligt och uppdaterat. llms.txt bör vara enkel att läsa och fokusera på det viktigaste. Skriv kortfattat, använd tydliga rubriker och uppdatera filen när innehållet på webbplatsen förändras.
- Se det som ett komplement, inte en ersättning. llms.txt ersätter inte robots.txt, sitemap, intern länkning eller schema markup. Det är ett extra lager som kan göra din webbplats lättare att tolka, men grunderna i teknisk SEO och innehållsstruktur är fortfarande viktigast. Google säger samtidigt att vanliga SEO-grunder fortsatt gäller för AI Overviews och AI Mode.
- Placera filen på rätt plats. Filen ska ligga i webbplatsens rotkatalog som /llms.txt, så att den är lätt att hitta och använda. Specifikationen beskriver även en kompletterande variant, llms-full.txt, för mer omfattande innehållsexport.
Det här steget är inte ett måste. Många LLM:er använder fortfarande inte llms.txt, men om du vill framtidssäkra din webbplats kan det ändå vara klokt att implementera filen redan nu. Det ger dig ett försprång om standarden får större genomslag längre fram.
Implementera och optimera schema markup
När du har säkerställt att AI-botar kan crawla din webbplats och dina viktigaste sidor är nästa steg att göra innehållet tydligare att tolka. Här blir schema markup viktigt. Strukturerad data hjälper sökmotorer och AI-system att förstå vad som finns på sidan, hur innehållet hänger ihop och vilka entiteter som är viktigast. Det ökar chanserna att informationen tolkas, sammanfattas och används på rätt sätt.
Implementera och optimera schema markup:
- Implementera grundläggande schema för varje innehållstyp. Använd relevant schema markup för de viktigaste sidtyperna på webbplatsen. Det kan till exempel vara Article, Product, FAQPage, HowTo eller VideoObject, beroende på vilken typ av innehåll sidan innehåller.
- Gå längre än en minimal implementation. Det räcker inte alltid att bara lägga till det mest grundläggande. Försök istället att bygga upp en så komplett och tydlig struktur som möjligt genom att fylla i relevanta egenskaper. Ju mer sammanhängande och informativ din schema markup är, desto lättare blir det för sökmotorer och AI-system att förstå innehållet korrekt.
- Skapa tydliga kopplingar mellan entiteter. Använd egenskaper som ‘’about’’, ‘’mentions’’ och ‘’sameAs’’ för att visa relationer mellan personer, företag, ämnen och andra viktiga entiteter. Det hjälper systemen att förstå sammanhanget på sidan och stärker tolkningen av relevans och auktoritet.
- Använd flera schematyper tillsammans när det behövs. I många fall räcker det inte med en enda schematyp. Genom att kombinera flera typer av schema markup kan du ge mer kontext och skapa en tydligare bild av sidans innehåll..
Schema markup är ett stort område, och detta är bara grunderna. Om du vill förstå strukturerad data på djupet och lära dig hur du implementerar det korrekt på din webbplats kan du läsa vidare här innan du fortsätter med resten av guiden.
AI-sök bygger i hög grad på frågor, sökintention och hur människor faktiskt formulerar sina behov. Innehåll som speglar det verkliga sättet människor söker på blir därför lättare för AI-system att förstå, hämta och sammanfatta. Ju bättre ditt innehåll matchar användarens fråga och avsikt, desto större är chansen att det används i AI-genererade svar.
Så bör du arbeta med longatil och konversationsfrågor:
- Analysera vilka frågor människor faktiskt ställer. Börja med att identifiera vilka långa och naturligt formulerade frågor som är vanliga i din nisch. Använd verkliga datakällor som sökdata, webbplatsens interna sökfunktion, supportärenden och kundfrågor. Det ger en tydligare bild av hur människor formulerar sina problem och vad de faktiskt vill ha svar på.
- Besvara frågan tidigt och tydligt. När du tar upp en viktig fråga i innehållet bör du ge ett tydligt svar direkt i början av avsnittet. Efter det kan du gå vidare med mer förklaring, exempel och fördjupning. Det gör innehållet lättare att förstå både för användare och AI-system.
- Bygg en tydlig FAQ-sektion. En välstrukturerad FAQ hjälper dig att fånga upp vanliga frågor i den form som användare faktiskt ställer dem. Det gör innehållet mer lättläst, mer sökbart och enklare för AI-system att tolka och återanvända.
- Optimera för följdfrågor. Moderna sökningar, särskilt i AI-verktyg, sker ofta i flera steg. En användare börjar kanske med frågan “Vad är bild-SEO?” och följer sedan upp med “Hur implementerar jag det på min sida?” eller “Ger det verkligen bättre SEO-resultat?” Därför bör du strukturera innehållet så att det inte bara svarar på den första frågan, utan också förutser nästa steg i användarens tankebana.
- Använd intern länkning för att fånga nästa fråga. När ett ämne leder vidare till nya frågor bör du länka vidare till relevanta fördjupningar, guider eller Q&A-sektioner. Det hjälper både användaren och sökmotorer att förstå hur innehållet hänger ihop.
När du förstår vilka frågor människor faktiskt ställer blir nästa steg att skapa innehåll som inte bara svarar på dem, utan gör det med verkligt djup, tydlig expertis och ett perspektiv som andra inte kan kopiera.
Strukturera innehåll så AI kan extrahera det
Du behöver inte optimera innehållet för varje enskild AI-modell. Det viktiga är i stället att strukturera informationen på ett sätt som gör den lätt att förstå, lyfta fram och återanvända. AI-system citerar sällan en hel artikel. Oftast hämtar de enskilda avsnitt, meningar, definitioner eller fakta. Ju tydligare och mer välstrukturerat ditt innehåll är, desto större är chansen att det blir citerat.
Så bör ditt innehåll vara uppbyggt:
- Utgå från riktiga frågor. Skapa innehåll kring ämnen som människor faktiskt söker efter. Fokusera särskilt på longtail-sökningar och konversationsfrågor, eftersom de ligger nära hur människor formulerar sig i AI-sök.
- Använd tydliga och beskrivande rubriker. Rubriker som “Siffror” eller “Tips” säger väldigt lite. En rubrik som “SEO-användarstatistik” eller “Varför är SEO viktigt?” gör det direkt tydligt vad avsnittet handlar om. Det hjälper både användare och AI-system att förstå innehållet snabbare.
- Börja varje avsnitt med det viktigaste svaret. Besvara frågan direkt i början av stycket eller avsnittet. Vänta inte till slutet med huvudpoängen. Om rubriken är “Varför är SEO viktigt?” bör första meningen ge ett kort och tydligt svar.
- Använd listor, punkter och tabeller där det passar. Information som presenteras i tydliga format är ofta lättare att tolka, analysera och citera än långa, täta textblock.
- Definiera viktiga begrepp tydligt. AI-system lyfter ofta fram korta och tydliga definitioner. Om du förklarar centrala termer på ett enkelt och precist sätt ökar chansen att just din formulering används.
- Använd konkreta siffror och fakta. Statistik, procentsatser och annan numerisk data gör innehållet mer trovärdigt och mer användbart. Det hjälper också AI-system att identifiera sidan som en källa för faktabaserad information.
- Visa alltid var informationen kommer ifrån. Tydliga källhänvisningar stärker innehållets trovärdighet. Det gör det lättare för både användare, sökmotorer och AI-system att lita på informationen.
- Uppdatera innehållet löpande. Ett välstrukturerat innehåll tappar i värde om informationen blir gammal. Att hålla fakta, exempel och statistik uppdaterade gör sidan mer relevant över tid.
Målet är alltså inte bara att skapa bra innehåll, utan att presentera det på ett sätt som gör det lätt att förstå, lyfta fram och återanvända. Ju tydligare, mer strukturerat och mer konkret ditt innehåll är, desto större är chansen att det blir synligt, citerat och värdefullt både i traditionell sök och i AI-genererade svar.
Använd interna länkar för att bygga sammanhang mellan de olika områden
Strategisk intern länkning är en av de mest grundläggande och viktigaste delarna av SEO. Det hjälper inte bara sökmotorer att förstå hur innehållet på din webbplats hänger ihop, utan gör det också lättare för AI-system att tolka relationen mellan olika ämnen, underämnen och din samlade expertis. En stark intern länkstruktur visar helt enkelt vad din webbplats kan, vad som hör ihop och vilka sidor som är viktigast.
Så bör du arbeta med intern länkning:
- Bygg innehållet i ämneskluster. Organisera webbplatsen kring en central pelarsida som täcker ett ämne brett, och komplettera den med flera undersidor som går djupare inom specifika delar av ämnet. Den här strukturen gör det lättare för både användare, sökmotorer och AI-system att förstå hur innehållet är uppbyggt och hur din expertis är fördelad.
- Länka mellan relaterade sidor på ett tydligt sätt. Interna länkar bör användas för att binda ihop sidor som hör ihop tematiskt. När relaterade artiklar, guider och resurser länkar till varandra blir ämnessambanden tydligare, samtidigt som användaren lättare hittar vidare till relevant fördjupning.
- Använd beskrivande ankartext. Undvik generiska formuleringar som “klicka här” eller “läs mer”. Använd i stället ankartexter som tydligt beskriver vad den länkade sidan handlar om. Det hjälper både användare och sökmotorer att förstå relationen mellan sidorna och stärker den semantiska kopplingen mellan ämnen.
- Lyft fram dina viktigaste sidor oftare. De sidor som är mest centrala för din webbplats bör också få flest och tydligast interna länkar. Det signalerar att de har högre betydelse och hjälper både sökmotorer och AI-system att förstå vilka sidor som bär upp din auktoritet inom ämnet.
Intern länkning bygger inte bara navigering, utan också sammanhang. Genom att koppla ihop relaterade sidor med tydlig ankartext och en logisk struktur hjälper du både sökmotorer och AI-system att förstå hur dina ämnen hänger ihop, vilka sidor som är viktigast och var din expertis finns.
Se till att den tekniska SEO-grunden fungerar
Teknisk SEO är grunden som gör det möjligt för både sökmotorer och AI-system att komma åt, förstå och tolka ditt innehåll korrekt. Om den tekniska grunden brister blir det svårare att indexera sidan, förstå innehållet och lyfta fram det i både traditionella sökresultat och AI-genererade svar. En stark teknisk grund kan därför bidra till både bättre synlighet och större chans att bli citerad. Google lyfter fortsatt fram Core Web Vitals som centrala mått för användarupplevelse och sidkvalitet.
Viktiga Core Web Vitals att optimera:
- Largest Contentful Paint (LCP). Mäter hur snabbt sidans viktigaste innehåll laddas. För en bra användarupplevelse bör LCP ske inom 2,5 sekunder från att sidan börjar laddas.
- Interaction to Next Paint (INP). Mäter hur snabbt sidan reagerar på användarens interaktioner. Ett bra värde är under 200 millisekunder. INP ersatte FID som Core Web Vital i mars 2024.
- Cumulative Layout Shift (CLS). Mäter den visuella stabiliteten under laddning. För att undvika att innehåll hoppar runt på sidan bör CLS vara lägre än 0,1.
- Var försiktig med JavaScript-tunga lösningar. Webbplatser som är starkt beroende av JavaScript kan göra det svårare för sökmotorer att rendera och förstå innehållet fullt ut. Därför bör viktigt innehåll vara lätt att nå och tydligt i den renderade sidan. Google säger också att dynamic rendering bara är en tillfällig lösning och inte en rekommenderad standardlösning, eftersom den skapar extra komplexitet.
I slutändan är teknisk SEO inte bara ett stöd, utan en förutsättning. När den tekniska grunden fungerar blir det lättare för både sökmotorer och AI-system att förstå, värdera och lyfta fram ditt innehåll. Vill du gå djupare i ämnet kan du läsa vår artikel om teknisk SEO.
Hur mäter man AI-söksynlighet?
När nya sökbeteenden växer fram behövs också nya sätt att mäta synlighet och framgång. I traditionell SEO har fokus länge legat på ranking, klick och trafik. I AI-sök fungerar det annorlunda. Med fler nollklickssökningar och svar som varierar beroende på hur frågan formuleras blir det svårare att följa en exakt position på samma sätt som i Google.
I stället behöver du mäta hur ofta, hur tydligt och i vilket sammanhang ditt varumärke förekommer i AI-genererade svar.
Det du behöver följa:
Nämnandeandel och närvaro i AI-verktyg
Det viktigaste måttet är hur ofta ditt varumärke, din produkt eller ditt innehåll nämns i AI-svar över ett stort antal relevanta frågor. Det kan ses som en form av omnämnandefrekvens eller share of voice i AI-sök. Ju oftare du förekommer, desto större synlighet har du i AI-miljöer.
Det du bör bedöma är:
- Hur ofta ditt varumärke eller din produkt nämns.
- Hur korrekt du/dina produkter beskrivs
- Om viktiga attribut kommer fram tydligt.
- Hur ofta du nämns jämfört med konkurrenter.
Extraktionsförmåga:
AI-system bygger ofta sina svar genom att hämta, omformulera och sammanfatta specifika delar av innehåll. Därför har sidor med tydlig struktur, klara huvudpoänger och välavgränsade avsnitt ofta större chans att användas i generativa svar.
Det du bör mäta:
- Om ditt innehåll citeras eller parafraseras i AI-svar.
- Om specifika stycken återkommer ofta.
- Hur ditt innehåll presenteras i AI-sammanfattningar.
Det här hjälper dig att förstå vilka delar av innehållet AI-modellerna tycker är mest värdefulla. Med den insikten kan du skapa mer av det som faktiskt blir upphämtat, sammanfattat och använt i AI-svar.
Referenstrafik från AI-plattformar
Även om många AI-sökningar slutar utan klick finns det fortfarande tillfällen då användare klickar sig vidare från ett AI-svar till en webbplats. Den trafiken är särskilt viktig att följa, eftersom den kan ge en tydligare bild av hur AI-synlighet faktiskt påverkar besök, engagemang och affärsresultat.
Det du bör spåra:
- Användare som kommer från AI-drivna plattformar och funktioner.
- Förändringar i trafiken efter att AI-svar börjat visas.
- Hur användarna beter sig efter landning.
- Om trafiken leder till konverteringar.
AI-synlighet handlar alltså inte bara om att bli nämnd, utan också om vad som händer efteråt. När ett klick väl sker blir det extra viktigt att förstå om trafiken skapar verkligt värde, särskilt i en miljö där varje besök är svårare att vinna.
Kombinerad SERP + AI synlighet
Både i dag och framåt kommer sök att vara hybrid. En och samma sida kan synas i traditionella sökresultat, bildsök, AI-svar och andra sökformat samtidigt. Det betyder att synlighet inte längre bara handlar om en enskild ranking, utan om hur väl du syns i hela söklandskapet. Tillsammans påverkar de här ytorna både hur lätt kunder upptäcker dig och hur mycket trafik du faktiskt kan få till webbplatsen.
Det du bör mäta
- Traditionell söksynlighet.
- Närvaro i AI-svar.
- Långsiktig stabilitet i SERP:en.
- Bildsynlighet
- Total synlighet för samma sökfråga.
Detta ger mer realistisk bild på hur din SEO situation är just nu och hur du presterar i hela systemet och inte bara i några delar
Vilka verktyg kan man använda för att mäta AI SEO?
Just eftersom AI SEO fortfarande är så nytt är det svårt att säga exakt vilka verktyg som är bäst. Det finns ännu inget enskilt standardverktyg som ger hela bilden på samma sätt som Search Console länge har gjort för traditionell sök. I praktiken behöver du därför kombinera flera datakällor för att förstå hur du faktiskt syns i AI-sök. Google beskriver Search Console som verktyget för att följa klick, visningar, CTR och position i Google Search, medan andra plattformar nu försöker mäta AI-synlighet, omnämnanden och share of voice i AI-svar.
Det betyder inte att dina vanliga SEO-verktyg har blivit irrelevanta. Tvärtom kan de fortfarande ge värdefull data. Search Console och Google Analytics är fortfarande viktiga för att följa traditionell söktrafik, landningssidor och användarbeteende på sajten, även om de inte ensamma kan visa hela AI-bilden. Google rekommenderar också att kombinera data från Search Console och Analytics för att analysera sökprestanda mer komplett.
Verktyg som är värda att använda
- Semrush har idag egna funktioner för att följa AI visibility och AI Overviews, och kan användas för att se hur ditt varumärke syns i AI-plattformar och Googles AI-funktioner.
- Ahrefs erbjuder verktyg för att mäta AI visibility, omnämnanden, citationer och share of voice i AI-sök.
- SE Ranking har också byggt verktyg för AI visibility där du kan följa omnämnanden, länkar och närvaro i AI-svar över tid.
- Screaming Frog är inte ett direkt AI-synlighetsverktyg, men det är fortfarande väldigt användbart för tekniska SEO-granskningar, crawling och att hitta problem som kan påverka både indexering och AI-läsbarhet.
Eftersom AI SEO fortfarande är i ett tidigt skede kommer inget verktyg att vara perfekt. Det viktigaste är därför inte att hitta ett enda “rätt” verktyg, utan att bygga en rimlig mätmodell med flera datakällor: traditionell sökdata, AI-synlighet, referenstrafik och teknisk hälsa.
Om du har teknisk kunskap kan du också gå ett steg längre och bygga en egen tracker. Det kräver mer tid och arbete, men det kan ge dig ett försprång när standardiserade lösningar fortfarande saknas. En egen lösning kan till exempel hjälpa dig att följa specifika prompts, AI-omnämnanden och förändringar över tid på ett sätt som passar just din verksamhet.
Vanliga misstag inom AI SEO
I takt med att AI-driven sökning utvecklas missförstår många marknadsförare hur generativa sökmotorer faktiskt fungerar. Det leder ofta till fel prioriteringar, onödigt arbete och sämre synlighet. Här är några av de vanligaste misstagen och varför de håller tillbaka arbetet med AI-sök.
Här är några vanliga misstag marknadsförare gör:
- De behandlar AI SEO som en helt separat disciplin. AI SEO är inte en helt ny bransch, utan snarare en vidareutveckling av klassisk SEO i nya sökmiljöer. När det behandlas som något helt fristående leder det ofta till splittrade processer, dubbelt arbete och strategier som inte hänger ihop.
- De blockerar AI-botar utan att inse det. Det här är ett av de vanligaste misstagen. Många webbplatser stoppar AI-crawlers via robots.txt, serverinställningar eller CDN-konfigurationer utan att vara medvetna om det. Om botarna inte kommer åt innehållet blir det betydligt svårare att synas i AI-sök.
- De gömmer viktigt innehåll bakom JavaScript eller interaktiva element. Innehåll som bara laddas in sent, ligger bakom flikar eller kräver interaktion kan bli svårare för botar att läsa och förstå. Om informationen är viktig bör den vara tydligt tillgänglig i sidans HTML.
- De låter innehållet bli inaktuellt. Innehåll som inte uppdateras riskerar att tappa i relevans över tid. Både sökmotorer och AI-system föredrar ofta information som är aktuell, korrekt och väl underhållen. Därför bör viktigt innehåll ses över och uppdateras regelbundet.
- De fokuserar för mycket på nyckelord och för lite på tydlighet. Generativa system försöker förstå innehållets betydelse, inte bara matcha ord. Otydliga förklaringar, svag struktur och röriga stycken gör det svårare för AI-system att tolka, extrahera och citera innehållet.
- De publicerar stora mängder tunt AI-genererat innehåll. Mer innehåll betyder inte automatiskt bättre resultat. Om artiklar saknar djup, tydliga källor, egen expertis eller verkligt värde blir de mindre användbara för både sökmotorer och AI-system. Volym utan kvalitet riskerar att skada mer än den hjälper.
- De försöker skriva för modeller istället för för människor. Genvägar och modellspecifika trick fungerar sällan särskilt länge. AI-system förändras snabbt, men tydligt, välstrukturerat och expertbaserat innehåll står sig över tid. Det är därför nästan alltid bättre att fokusera på kvalitet än på tillfälliga taktiker.
De här misstagen förekommer i många branscher, och AI SEO är inget undantag. Ju tidigare du identifierar dem, desto lättare blir det att undvika att lägga tid och resurser på sådant som inte ger resultat.
Framtiden för AI SEO
Många pratar i dag om AI SEO, GEO och andra nya begrepp som om det vore ett helt nytt och väldigt komplicerat område. Men i grunden handlar AI SEO fortfarande om SEO. Det är inte något helt nytt, utan snarare en vidareutveckling av det som redan finns.
AI-system är visserligen bättre på att förstå sökintention, tolka frågor och hantera konversationer, men de bygger fortfarande sina svar på samma grundprincip: att lyfta fram de mest relevanta och trovärdiga källorna. Och de källorna är ofta desamma som redan presterar bra i traditionell sök. Innehåll som inte anses tillräckligt starkt för att synas högt i sökresultaten har också mindre chans att bli citerat i AI-genererade svar.
För att lyckas behöver du därför fortfarande göra det klassiska SEO-arbetet ordentligt. Det innebär att se till att AI-botar kan läsa webbplatsen, strukturera innehållet så att det blir lätt att förstå och extrahera, använda schema markup, ge tydliga svar på riktiga användarfrågor och bygga starka ämneskluster med hjälp av intern länkning. Samtidigt måste den tekniska SEO-grunden vara på plats, eftersom snabbhet, crawlbarhet och tydlig HTML-struktur fortfarande är avgörande.
SEO är alltså långt ifrån dött. Tvärtom. Vill du synas och bli citerad i AI-verktyg måste du förstå SEO på riktigt. Annars är risken stor att du lägger tid på trender, begrepp och implementationer som i praktiken inte gör någon verklig skillnad.
Vanliga Frågor (FAQ)
Vad är AI SEO?
AI SEO handlar om att optimera din webbplats och ditt innehåll så att det lättare kan upptäckas, förstås, citeras och användas av AI-drivna sökmotorer och AI-svar, som exempelvis Google AI Overviews, ChatGPT, Gemini och Copilot.
Är AI SEO samma sak som vanlig SEO?
Nej, men de hänger nära ihop. AI SEO bygger vidare på klassisk SEO. Grunder som bra innehåll, tydlig struktur, teknisk kvalitet och auktoritet är fortfarande viktiga. Skillnaden är att AI-sök också fokuserar på om ditt innehåll blir använt i själva svaret, inte bara om det rankar högt.
Varför är AI SEO viktigt?
Sökbeteendet förändras snabbt. Allt fler användare får svar direkt i AI-gränssnitt utan att klicka vidare till en webbplats. Om ditt innehåll inte syns i AI-genererade svar riskerar du att tappa synlighet, trafik och affärsmöjligheter.
Hur fungerar AI-sök?
AI-sök fungerar ofta i flera steg: först tolkas frågan, sedan hämtas relevanta källor, därefter rangordnas innehållet och till sist genereras ett svar. I många fall väger systemet ihop flera olika källor till ett enda sammanfattat svar.
Vad är skillnaden mellan AI-sök och traditionell sökning?
Traditionell sökning visar oftast en lista med länkar. AI-sök försöker i stället förstå frågan, hämta relevant information och ge ett direkt svar. Det betyder att synlighet inte bara handlar om placering, utan också om att bli citerad eller refererad i AI-svaret.
Behöver jag välja mellan traditionell SEO och AI SEO?
Nej. Den bästa strategin är att kombinera båda. Klassisk SEO är fortfarande grunden, medan AI SEO hjälper dig att bli synlig i nya sökmiljöer där AI spelar en större roll.
Hur gör jag mitt innehåll mer synligt i AI-sök?
Börja med att säkerställa att AI-botar kan crawla din webbplats. Därefter bör du skapa tydligt, välstrukturerat och hjälpsamt innehåll som svarar på riktiga frågor. Tydliga rubriker, konkreta svar, stark intern länkning och strukturerad data gör innehållet lättare för AI-system att förstå och använda.
Ska jag ha en FAQ-sektion på min webbplats?
Ja, ofta är det en bra idé. En välstrukturerad FAQ hjälper dig att fånga upp vanliga frågor i ett format som både användare och AI-system lätt kan förstå, tolka och återanvända.
Vad är llms.txt?
llms.txt är en föreslagen filstandard som ska hjälpa språkmodeller att snabbare förstå en webbplats struktur och viktigaste innehåll. Den är inte ett måste, men kan fungera som ett komplement till exempelvis robots.txt, sitemap och intern länkning.
Är llms.txt nödvändigt för att synas i AI-sök?
Nej, inte i dagsläget. Många AI-system använder fortfarande inte llms.txt fullt ut. Men det kan vara ett sätt att framtidssäkra webbplatsen och göra innehållet lättare att tolka om standarden får större genomslag.
Hur mäter man synlighet i AI-sök?
I stället för att bara mäta rankning och klick behöver du följa hur ofta ditt varumärke, din produkt eller ditt innehåll nämns i AI-svar. Du bör också mäta referenstrafik från AI-plattformar, hur innehåll citeras och hur synligheten ser ut i både AI-svar och vanliga sökresultat.
Vad är det viktigaste att börja med inom AI SEO?
Börja med grunderna: se till att webbplatsen kan crawlas, att innehållet är tydligt strukturerat, att viktiga frågor besvaras direkt och att den tekniska SEO:n fungerar. Därefter kan du stärka upp med schema markup, intern länkning och bättre mätning av AI-synlighet.
Referenslista
- 1. Chapekis, A., & Lieb, A. (2025, July 22). Google users are less likely to click on links when an AI summary appears in the results. Pew Research Center. https://www.pewresearch.org/short-reads/2025/07/22/google-users-are-less-likely-to-click-on-links-when-an-ai-summary-appears-in-the-results/
- 2. Cloudflare, Inc. (2025, July 1). Cloudflare just changed how AI crawlers scrape the internet-at-large; Permission-based approach makes way for a new business model. https://www.cloudflare.com/en-gb/press/press-releases/2025/cloudflare-just-changed-how-ai-crawlers-scrape-the-internet-at-large/
- 3. Dean, B. (2025, May 15). Google’s 200 ranking factors: The complete list. Backlinko. https://backlinko.com/google-ranking-factors
- 4. Eriksson, V. (2025, July 22). Open AI avslöjar hur många instruktioner Chat GPT hanterar varje dag. PC för Alla. https://www.pcforalla.se/article/2854768
- 5. Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2024). RAGAs: Automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations (pp. 150–158). Association for Computational Linguistics.
- 6. Fishkin, R. (2024, July 1). 2024 zero-click search study: For every 1,000 EU Google searches, only 374 clicks go to the open web. In the US, it’s 360. SparkToro. https://sparktoro.com/blog/2024-zero-click-search-study-for-every-1000-us-google-searches-only-374-clicks-go-to-the-open-web-in-the-eu-its-360/
- 7. Formal, T., Piwowarski, B., & Clinchant, S. (2021). SPLADE: Sparse lexical and expansion model for first stage ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 2288–2292). ACM.
- 8. Gao, T., Yen, H., Yu, J., & Chen, D. (2023). Enabling large language models to generate text with citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 6465–6488). Association for Computational Linguistics.
- 9. Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Guo, Q., Wang, M., & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey.
- 10. Google. (2025, December 10). AI features and your website. Google Search Central. https://developers.google.com/search/docs/appearance/ai-features
- 11. Google. (2025, December 10). Introduction to structured data markup in Google Search. Google Search Central. https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
- 12. Google Search Central. (2025, December 10). AI features and your website.
- 13. Harris, Z. S. (1954). Distributional structure. Word, 10(2–3), 146–162.
- 14. Joachims, T., Granka, L. A., Pan, B., Hembrooke, H., & Gay, G. (2005). Accurately interpreting clickthrough data as implicit feedback. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 154–161). ACM.
- 15. Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., & Yih, W.-t. (2020). Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 6769–6781). Association for Computational Linguistics.
- 16. Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and effective passage search via contextualized late interaction over BERT. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 39–48). ACM.
- 17. Le, Q. V., & Mikolov, T. (2014). Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning (pp. 1188–1196).
- 18. Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474.
- 19. Li, H., & Xu, J. (2014). Semantic matching in search. Foundations and Trends in Information Retrieval, 7(5), 343–469.
- 20. Liu, T.-Y. (2009). Learning to rank for information retrieval. Foundations and Trends in Information Retrieval, 3(3), 225–331.
- 21. Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query rewriting in retrieval-augmented large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 5303–5315). Association for Computational Linguistics.
- 22. Makun. (2026, March 23). Strukturerad data och SEO: Din guide till försprång 2026. https://makun.se/strukturerad-data/
- 23. Melton, W. (2025, November 16). Google AI Overviews clear 60% as new data suggests ChatGPT will surpass Google Search traffic by 2027. Xponent21. https://xponent21.com/insights/google-ai-overviews-surpass-60-percent/
- 24. Mitra, B., Diaz, F., & Craswell, N. (2017). Learning to match using local and distributed representations of text for web search. In Proceedings of the 26th International Conference on World Wide Web (pp. 1291–1299). International World Wide Web Conferences Steering Committee.
- 25. Nguyen, T., Rosenberg, M., Song, X., Gao, J., Tiwary, S., Majumder, R., & Deng, L. (2016). MS MARCO: A human generated machine reading comprehension dataset. In Proceedings of the Workshop on Cognitive Computation: Integrating Neural and Symbolic Approaches 2016 (Vol. 1773). CEUR Workshop Proceedings.
- 26. Nogueira, R., & Cho, K. (2019). Passage re-ranking with BERT.
- 27. Pandya, V. (2025, August 21). Adobe: Generative AI-powered shopping rises with traffic to U.S. retail sites up 4,700%. Adobe for Business Blog. https://business.adobe.com/blog/generative-ai-powered-shopping-rises-with-traffic-to-retail-sites
- 28. Rajpurkar, P., Zhang, J., Lopyrev, K., & Liang, P. (2016). SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (pp. 2383–2392). Association for Computational Linguistics.
- 29. Richardson, M., Burges, C. J. C., & Renshaw, E. (2013). MCTest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (pp. 193–203). Association for Computational Linguistics.
- 30. Robertson, S. E., & Zaragoza, H. (2009). The probabilistic relevance framework: BM25 and beyond. Foundations and Trends in Information Retrieval, 3(4), 333–389.
- 31. Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 85–117.
- 32. Silliman, E., Boudet, J., Robinson, K., Oppong, D., & Shah, N. (2025, October 16). New front door to the internet: Winning in the age of AI search. McKinsey & Company. https://www.mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/new-front-door-to-the-internet-winning-in-the-age-of-ai-search
- 33. Thakur, N., Reimers, N., Rücklé, A., Srivastava, A., & Gurevych, I. (2021). BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
- 34. Voorhees, E. M., & Tice, D. M. (2000). Building a question answering test collection. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 200–207). ACM.
- 35. Wang, L., Yang, N., & Wei, F. (2023). Query2doc: Query expansion with large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 9414–9423). Association for Computational Linguistics.
- 36. White, R. W. (2016). Interactions with search systems. Cambridge University Press.
- 37. Zhu, Y., Yuan, H., Wang, S., Liu, J., Liu, W., Deng, C., Chen, H., Liu, Z., Dou, Z., & Wen, J.-R. (2023). Large language models for information retrieval: A survey.